Índice
Visão Geral
O reconhecimento automático de fala (ASR) pode ser definido como a habilidade de uma máquina ou programa de software de identificar palavras e frases em linguagem falada e convertê-las para um formato que seja manuseável ou legível para o computador. Ou seja, um sistema ASR toma um sinal de fala digitalizado como entrada e gera um texto transcrito na saída. O esquema abaixo ilustra os principais blocos de um sistema de reconhecimento de fala tradicional.
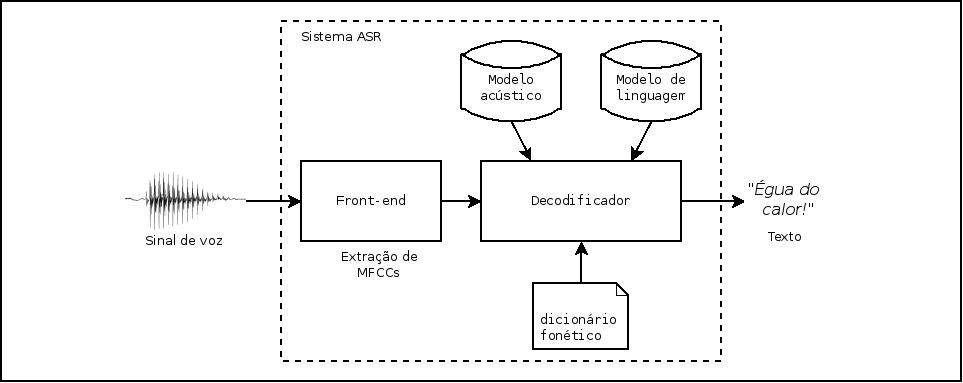
TODO: talk a little about each block to introduce next subsects
G2P: dicionário fonético
O dicionário fonético (também conhecido como modelo léxico) oferece um mapeamento de grafemas para fonemas. De forma simplificada, grafema são as palavras da forma que conhecemos (com letras do alfabeto) e fonemas são unidades básicas que descrevem como um particular som em determinado idioma é pronunciado. Um exemplo de conversão grafema-fonema (G2P) é mostrado no dicionário abaixo:
edson e dZ s o~ carla k a X l a
achou a S o w gosta g o s t a
uma u~ m a de dZ i
galinha g a L i~ J a sapatos s a p a t u s
vermelha v e R m e L a brancos b r a~ k u s
AM: modelo acústico
O modelo acústico (AM) fornece um mapeamento de cada fonema para uma representação sonora extraída de arquivos de áudio. Técnicas de aprendizado de máquina são frequentemente empregadas para treinar modelos ocultos de Markov (HMMs) e modelos de misturas de Gaussianas (GMMs) para serem “armazenados” no AM. Um modelo bastante simplificado pode ser visto na imagem abaixo, onde a palavra “PALAVRA” (e seus respectivos fonemas) está alinhada com o correspondente áudio falado.
TODO: insert fig and change eg word above
LM: modelo de linguagem
O modelo de linguagem (LM) descreve a probabilidade de ocorrência de uma
determinada palavra baseado nas n-1 palavras anteriores (modelo n-grama, onde
tipicamente n=3 para os famosos modelos trigrama). Por exemplo, a sentença “a
casa é vermelha” teria mais probabilidade de ocorrer do que “a casa é ovelha”.
Portanto:
$$ P(\text{“vermelha”}|\text{“a casa é”}) \gt P(\text{“ovelha”}|\text{“a casa é”}) $$
Apesar de LMs serem necessários para treinar um sistema ASR do começo, talvez eles sejam usados em ambientes de produção somente quando se está lidando com aplicações baseadas na tarefa de ditado (normalmente milhares de palavras contidas no vocabulário). No entanto, se a aplicação envolve comando e controle, pode ser mais interessante trabalhar com gramáticas livre-de-contexto ao invés de modelos de língua n-grama.
Gram: gramática livre de contexto
Coming soon.
Recursos ASR no GitLab do FalaBrasil
Recursos prontos
https://gitlab.com/fb-asr/fb-asr-resources
Tutoriais para treinamento de AMs
https://gitlab.com/fb-asr/fb-am-tutorial
Tutoriais para treinamento de LMs
https://gitlab.com/fb-asr/fb-lm-tutorial
| Toolkit | Link |
|---|---|
| SRILM | coming soon |